
现在,人类越来越想让“冯·诺依曼架构”退休了。因为存储墙和功耗墙问题,冯·诺依曼架构愈发触碰瓶颈。
类脑芯片就是突破“冯·诺依曼架构”的路线之一,它一种高度模拟人脑计算原理的芯片。如果把类脑芯片做得更像人脑,就会被赋予一个新的名字——神经拟态计算/神经形态计算(Neuromorphic Computing),它是数字芯片和AI计算的一条重要发展路线。
神经拟态计算被视为颠覆边缘AI行业的存在,因为它的功耗实在是太低了。完美的神经拟态芯片可以用比传统解决方案低1000倍的能耗来解决问题,这意味着我们可以在固定的功耗预算下,打包更多的芯片来解决更大规模的问题。
当然,现在的神经拟态计算还达不到这样的程度,但给现有芯片降低几倍或者几十倍功耗的能力还是有的。比如,IBM此前推出的类脑芯片“北极”(NorthPole),对比4nm节点实现的Nvidia H100 GPU相比,NorthPole的能效提高了五倍。
现在,神经拟态也开始渗入了边缘AI领域,甚至是改变MCU。
Innatera推出首款商用类脑MCU
最近,初创公司Innatera宣布推出一款名为Pulsar的新型脉冲神经处理器(SNP)。Pulsar 是一种神经形态信号处理器,旨在以高能效执行边缘AI推理,与传统的AI处理器相比,新处理器的延迟降低了100倍。
此外,从功耗角度来看,该系统使用内部低功耗PLL和软件控制的电压域来降低动态和待机功耗。多种睡眠模式进一步优化了空闲期间的能量消耗。Innatera声称该处理器的能耗比传统的AI处理器低500倍。
Pulsar的底层架构集成了完全可编程的脉冲神经网络(SNN)结构,针对异步、稀疏数据计算进行了优化。为此,Pulsar提供了异构计算架构,将SNN、CNN和传统CPU任务分开,以优化工作负载分区。
Innatera将处理器设计为灵活的,支持跨不同网络拓扑的神经元和突触级参数化,以专门满足音频和振动传感等时空工作负载的需求。为了支持混合工作负载,SNN结构与支持浮点的32位RISC-V CPU和32-MAC CNN加速器一起运行。FFT/IFFT引擎为时频域应用提供了额外的计算能力。
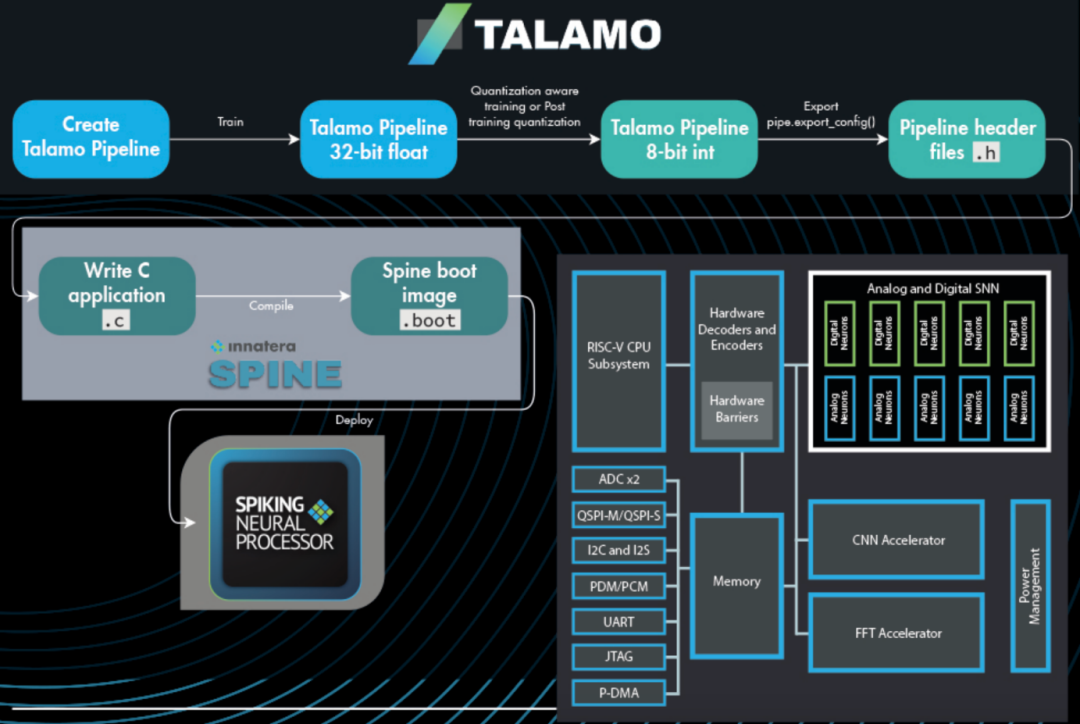
该处理器的内存子系统包括384 KB通用SRAM、128 KB专用于CNN计算和32 KB保留 SRAM,以通过低功耗转换保持应用程序状态。集成的外设支持包括I2C、UART、SPI、JTAG、ADC、摄像头接口和GPIO,由分散收集DMA引擎提供支持,以促进尖峰数据处理。供电电压为1.6V,系统频率为160MHz,封装尺寸为2.8mm x 2.6mm/36pin WLCSP,工作温度-40℃~125℃。
软件端,Pulsar由Talamo SDK提供支持,它将基于PyTorch的模型训练与直接硬件映射集成在一起。开发人员可以使用Python原生编译器或RISC-V的标准GCC工具链来部署模型。
Polyn首款神经拟态模拟信号处理芯片流片
最近,Polyn Technology宣布其首款基于专有神经拟态模拟信号处理平台(Neuromorphic Analog Signal Processing, NASP)模拟芯片正式流片成功,同时NASP芯片进入认证阶段,并预计于2025年第二季度正式投放市场。
这款芯片实现了超低功耗和实时信号处理能力,在执行信号推理时的功耗低于100μW,某些应用场景如 NeuroVoice VAD模型甚至可降至30μW。如此低的能耗使其非常适合应用于耳机、可穿戴设备、智能轮胎以及预测性维护传感器节点等功耗受限的环境中。此外,NASP可将原始数据量缩减高达1000倍,显著提升隐私保护水平,减少对云服务的依赖,尤其适合医疗健康等对数据安全要求极高的领域。在技术资料中,NASP放出了在推理MobileNet V.2时候对比树莓派3B+和JETSON TX1的结果。

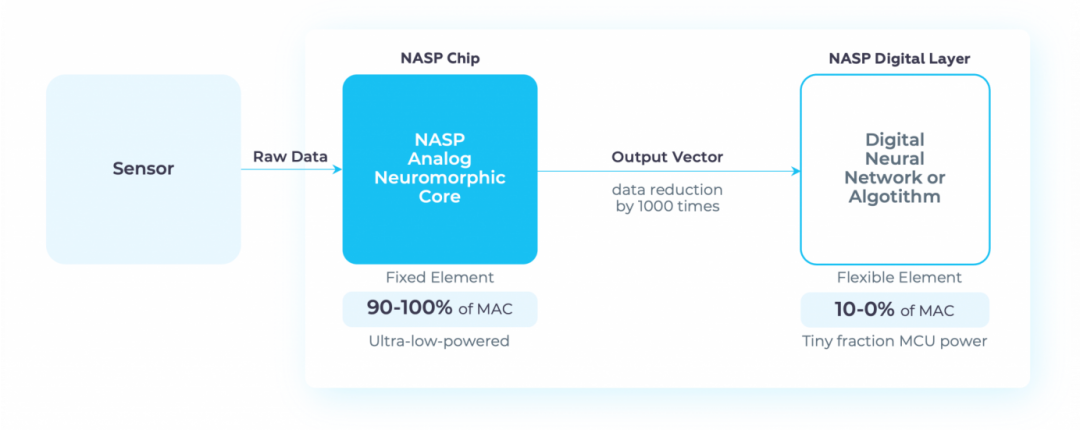
NASP是Polyn技术创新的核心。它是一种混合模拟-数字架构,通过模拟电路模仿生物神经元的分布式、超并行操作。该系统由运算放大器和可编程电阻组成,能够在不依赖中央处理器或对信号进行数字化预处理的前提下,直接对传感器数据进行原生推理。
与传统传感器数据处理方式不同,NASP前端可在原始音频输入阶段就进行过滤与压缩,仅输出用于后续处理的关键特征向量。这种方式不仅提升了效率,更实现了对信号的“理解”,从而显著降低带宽需求和云端依赖。
当它充当边缘信号传感器,能够使用神经拟态计算处理原始传感器数据,而无需对模拟信号进行任何数字化。出于这个原因,该公司将其称为第一款无需模数转换器(ADC)即可直接在传感器旁边使用的神经拟态模拟TinyML芯片。
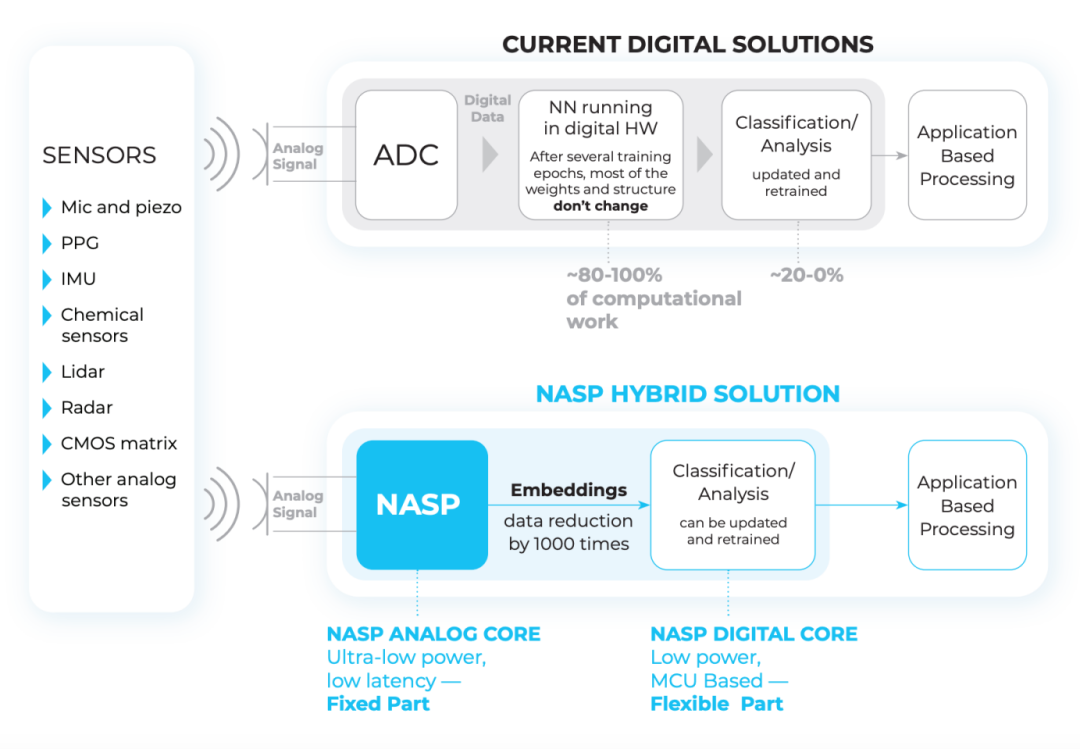
NASP 平台采用“固定 + 灵活”的双模块结构:
固定部分:通过硬连线模拟电路实现,负责从原始传感器数据中提取关键特征;
灵活部分:采用标准数字逻辑或低功耗微控制器实现,负责分类与解释。
这一混合架构将迁移学习引入硬件层面。开发人员只需重新训练灵活部分,即可快速适配新任务,例如将原本用于步态识别的加速度计数据用于跌倒检测,从而大幅缩短产品迭代周期并降低整体复杂度。
Polyn不仅为NASP自主研发了编译器工具链,同时在设计流程上,Polyn利用Cadence的Virtuoso和Innovus工具,整合模拟与数字电路设计,并在55纳米CMOS工艺上实现流片。
目前,Polyn正与SkyWater、普利司通、英飞凌、TDK等行业领先企业展开深度合作。虽然其首款芯片专注于语音处理,但未来的潜在应用场景包括振动分析、生物信号解读、人机交互等多个领域。
2023年12月,英飞凌曾披露与Polyn的合作,双方正在合作开发高级轮胎监测产品,英飞凌将提供具有轮胎振动信号检测功能的新一代TPMS传感器,并利用Polyn的NFE 对传感器的振动数据进行预处理。

弗劳恩霍夫开发出边缘AI加速器
今年3月,弗劳恩霍夫集成电路研究所 IIS 开发了一种用于处理脉冲神经网络(SNN)的AI 芯片。脉冲神经网络SENNA的推理加速器受到大脑功能的启发,由人工神经元组成,可以直接处理电脉冲(尖峰)。其速度、能效和紧凑的设计使得直接在生成数据的地方(即边缘设备)中使用SNN成为可能。
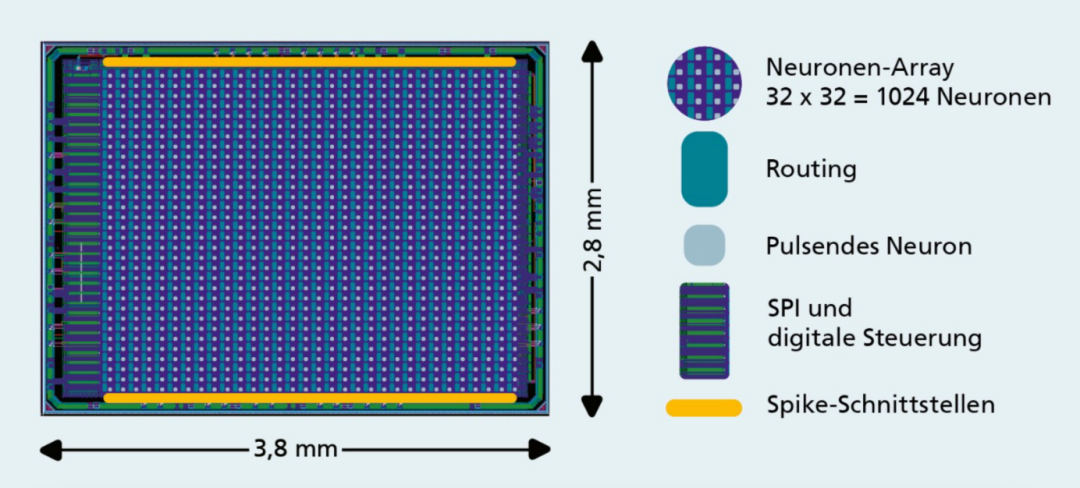
SENNA是一种神经拟态芯片,用于在AI应用中快速处理低维时间序列数据。其当前版本由1024个人工神经元组成,芯片面积小于11 mm²。该芯片的响应时间短至 20纳秒,可确保精确计时,尤其是在边缘时间关键型应用中。
因此,它的优势在基于事件的传感器数据的实时评估和闭环控制系统中真正显现出来;例如,在使用AI控制小型电动机时。SENNA还可用于在通信系统中实现AI优化的数据传输。在那里,AI处理器可以分析信号流并根据需要调整传输和接收程序,以提高传输的效率和性能。

SNN如此节能的原因之一是神经元仅被少量激活,并且响应特定事件。通过其尖峰神经元,SENNA 充分利用了这一节能优势。由于其完全并行的处理架构,人工神经元可以精确地映射SNN的时间行为。SENNA还可以通过其集成的尖峰接口直接处理基于尖峰的输入和输出信号。通过这种方式,它可以无缝地适应基于事件的数据流。“凭借其新颖的架构,SENNA 解决了能效、处理速度和多功能性之间的权衡,这是其他边缘 AI 处理器所无法比拟的。这使得它非常适合资源受限的应用,这些应用需要在纳秒范围内具有极快的响应时间,“Fraunhofer IIS嵌入式AI集团经理 Michael Rothe解释道。
当前的SENNA参考设计专为22nm制造工艺而设计。这意味着SNN处理器可以用作各种应用中的芯片,并且可以经济高效地实现。它的设计是可扩展的,可以在芯片生产之前适应特定应用、性能要求和目标硬件的特殊功能。但即使在芯片制造完成后,SENNA仍保留了最大的灵活性,因为它是完全可编程的。使用的SNN模型可以一次又一次地更改并重新传输到 SENNA。为了让开发人员尽可能轻松地实现他们的AI模型,Fraunhofer IIS 还为 SENNA提供了一个全面的软件开发工具包。
神经拟态到底是啥
目前全世界的神经拟态芯片结构基本都一致,都是由神经元计算、突触权重存储、路由通信三部分构成。不过,比较关键的点在于亮点——一是模型,二是器件。
首先,在模型方面,目前神经拟态芯片普遍采用SNN(脉冲神经网络)。相较于传统神经网络,脉冲神经网络(SNN)的结构更具“神经”特性。传统神经网络依赖矩阵卷积或矩阵乘法实现信号传播,而SNN在传播过程中采用了更贴近人类大脑的神经突触结构。在SNN 网络中,当脉冲信号积累至特定水平时,神经元会向下一个神经元发送代表“1”的信号,随后自身膜电位恢复至较低水平,并在一段时间内进入不应期,无法再次发送信号。
对于SNN来说,时空动态性是一个重要的特性。通过引入时间维度,SNN能实现异步计算。SNN擅长处理时空动态信息,尤其适合与事件驱动型传感器(如动态视觉传感器DVS)结合。目前来看,大多数厂商都选择SNN+CNN的异构方案,应对不同场景。
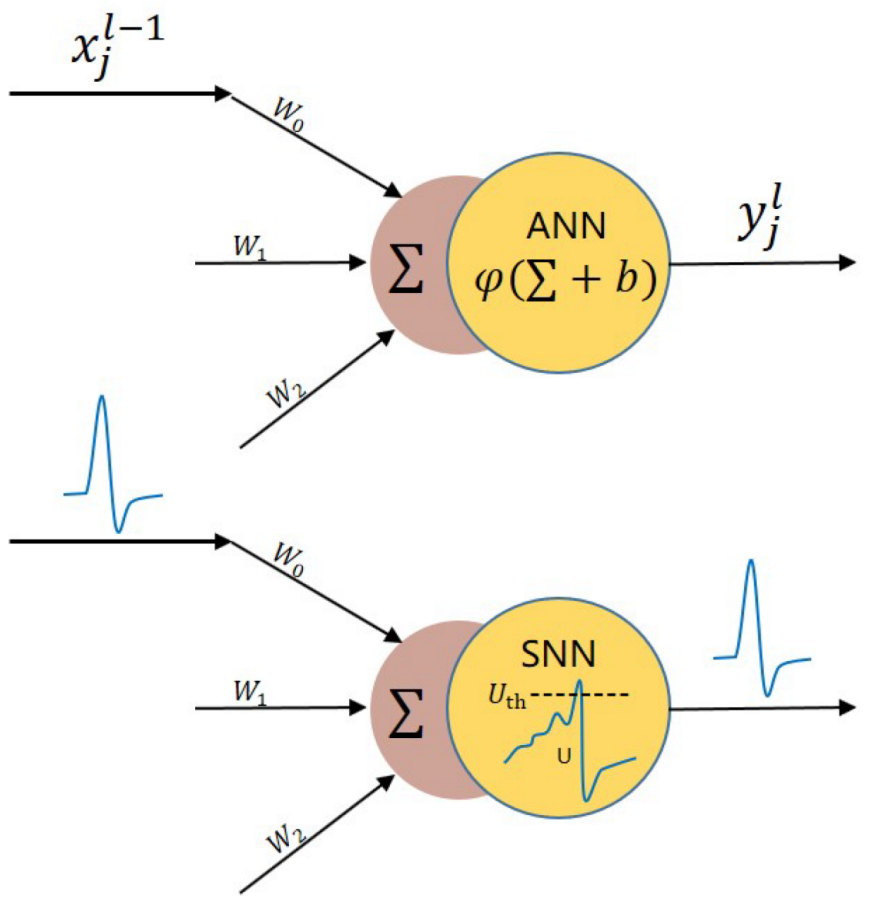
其次,在器件实现,依据材料、器件、电路,分为模拟电路主导的神经形态系统(数模混合CMOS型)、全数字电路神经系统(数字CMOS型)、基于新型器件的数模混合神经形态系统(忆阻器是候选技术)三种流派。
数字CMOS是目前最易产业化的形式,一方面,技术和制造成熟度高,另一方面,不存在模拟电路的一些顾虑和限制,不过数字CMOS型还只是最初阶的类脑芯片,还算不上完全模拟人脑的神经形态器件。
数模混合CMOS是Polyn的实现方式,通过对比来看,这种方式能够直接省略掉ADC,可以通过可编程电阻直接对传感器的原生数据进行处理。
忆阻器(Memristor)则是目前科学界也在研究的技术,忆阻器的魅力在于,它不仅是一个存储单元,同时还能进行计算!想象一下,如果你的硬盘不仅能存储数据,还能直接进行深度学习计算,那么 AI 训练的速度将大幅提升。忆阻器的这一特性,使其成为存算一体架构的核心组件。忆阻器存算一体架构正在快速发展,预计在未来5~10年内将进入商业化应用。
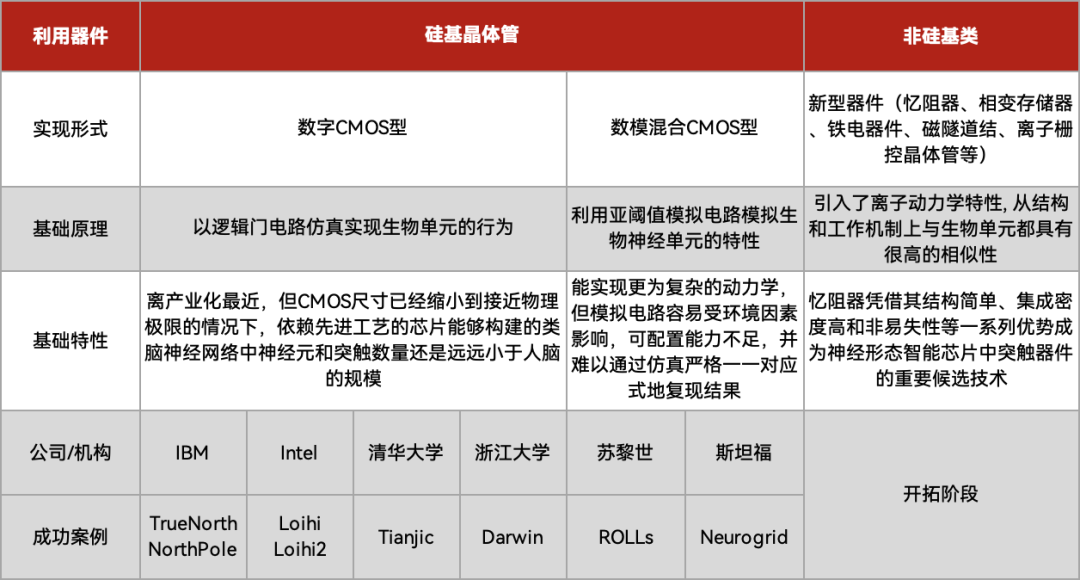
类脑芯片主要类型和研发进度,制表丨电子工程世界
目前,国内也有很多企业在研究神经拟态计算芯片,他们的主要目标也是边缘AI。
国内研究则包括清华大学、浙江大学、复旦大学、中科院等顶级学府和机构,同时近两年不断涌现初创公司,如灵汐科技、时识科技、中科神经形态等。其中以清华大学的天机芯和浙江大学的达尔文芯片最具代表性。

边缘AI正在被颠覆
总之,受人脑启发的神经拟态计算正在颠覆边缘AI场景。
与传统的冯·诺依曼架构不同,神经形态芯片模拟人脑的神经元和突触结构,具有超低功耗和并行处理能力,特别适合边缘设备上的AI应用。
毕竟,动不动就上百倍能效提升,可太香了,谁不想要。
目前,英特尔的Loihi、IBM的TrueNorth等神经形态芯片已展示出在边缘AI场景下的巨大潜力。
而上文介绍的厂商也已经开始正式在商业化场景中尝试使用神经拟态芯片,虽然出于成本、开发难度等考量,可能他们并不会完全取代现有的MCU或嵌入式芯片,但在特定场景一定能够得到很强的应用。一场边缘新革命即将到来。








暂无评论内容